- Email support@dumps4free.com

An ML engineer is using a training job to fine-tune a deep learning model in Amazon
SageMaker Studio. The ML engineer previously used the same pre-trained model with a
similar
dataset. The ML engineer expects vanishing gradient, underutilized GPU, and overfitting
problems.
The ML engineer needs to implement a solution to detect these issues and to react in
predefined ways when the issues occur. The solution also must provide comprehensive
real-time metrics during the training.
Which solution will meet these requirements with the LEAST operational overhead?
A. Use TensorBoard to monitor the training job. Publish the findings to an Amazon Simple Notification Service (Amazon SNS) topic. Create an AWS Lambda function to consume the findings and to initiate the predefined actions.
B. Use Amazon CloudWatch default metrics to gain insights about the training job. Use the metrics to invoke an AWS Lambda function to initiate the predefined actions.
C. Expand the metrics in Amazon CloudWatch to include the gradients in each training step. Use the metrics to invoke an AWS Lambda function to initiate the predefined actions.
D. Use SageMaker Debugger built-in rules to monitor the training job. Configure the rules to initiate the predefined actions.
Explanation:
SageMaker Debugger provides built-in rules to automatically detect issues like vanishing
gradients, underutilized GPU, and overfitting during training jobs. It generates real-time
metrics and allows users to define predefined actions that are triggered when specific
issues occur. This solution minimizes operational overhead by leveraging the managed
monitoring capabilities of SageMaker Debugger without requiring custom setups or
extensive manual intervention.
A company stores historical data in .csv files in Amazon S3. Only some of the rows and
columns in the .csv files are populated. The columns are not labeled. An ML
engineer needs to prepare and store the data so that the company can use the data to train
ML models.
Select and order the correct steps from the following list to perform this task. Each step
should be selected one time or not at all. (Select and order three.)
• Create an Amazon SageMaker batch transform job for data cleaning and feature
engineering.
• Store the resulting data back in Amazon S3.
• Use Amazon Athena to infer the schemas and available columns.
• Use AWS Glue crawlers to infer the schemas and available columns.
• Use AWS Glue DataBrew for data cleaning and feature engineering.
A company has a binary classification model in production. An ML engineer needs to
develop a new version of the model.
The new model version must maximize correct predictions of positive labels and negative
labels. The ML engineer must use a metric to recalibrate the model to meet these
requirements.
Which metric should the ML engineer use for the model recalibration?
A. Accuracy
B. Precision
C. Recall
D. Specificity
Explanation: Accuracy measures the proportion of correctly predicted labels (both positive and negative) out of the total predictions. It is the appropriate metric when the goal is to maximize the correct predictions of both positive and negative labels. However, it assumes that the classes are balanced; if the classes are imbalanced, other metrics like precision, recall, or specificity may be more relevant depending on the specific needs.
An ML engineer is working on an ML model to predict the prices of similarly sized homes.
The model will base predictions on several features The ML engineer will use the following
feature engineering techniques to estimate the prices of the homes:
• Feature splitting
• Logarithmic transformation
• One-hot encoding
• Standardized distribution
Select the correct feature engineering techniques for the following list of features. Each
feature engineering technique should be selected one time or not at all (Select three.)
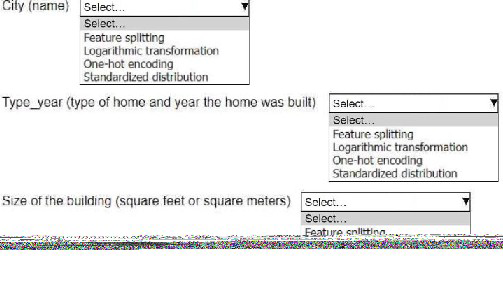
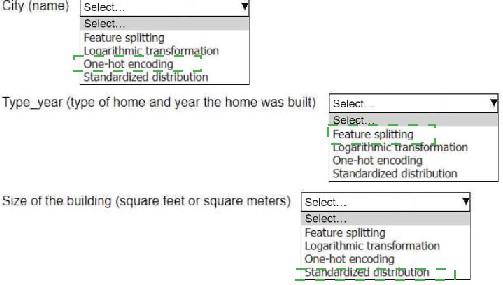
Explanation:
City (name):One-hot encoding
Type_year (type of home and year the home was built):Feature splitting
Size of the building (square feet or square meters):Standardized distribution
City (name): One-hot encoding
Type_year (type of home and year the home was built): Feature splitting
Size of the building (square feet or square meters): Standardized distribution
By applying these feature engineering techniques, the ML engineer can ensure that the
input data is correctly formatted and optimized for the model to make accurate predictions.
A company is running ML models on premises by using custom Python scripts and
proprietary datasets. The company is using PyTorch. The model building requires unique
domain knowledge. The company needs to move the models to AWS.
Which solution will meet these requirements with the LEAST effort?
A. Use SageMaker built-in algorithms to train the proprietary datasets.
B. Use SageMaker script mode and premade images for ML frameworks.
C. Build a container on AWS that includes custom packages and a choice of ML frameworks.
D. Purchase similar production models through AWS Marketplace.
Explanation:
SageMaker script mode allows you to bring existing custom Python scripts and run them on
AWS with minimal changes. SageMaker provides prebuilt containers for ML frameworks
like PyTorch, simplifying the migration process. This approach enables the company to
leverage their existing Python scripts and domain knowledge while benefiting from the
scalability and managed environment of SageMaker. It requires the least effort compared
to building custom containers or retraining models from scratch.
An ML engineer needs to implement a solution to host a trained ML model. The rate of
requests to the model will be inconsistent throughout the day.
The ML engineer needs a scalable solution that minimizes costs when the model is not in
use. The solution also must maintain the model's capacity to respond to requests during
times of peak usage.
Which solution will meet these requirements?
A. Create AWS Lambda functions that have fixed concurrency to host the model. Configure the Lambda functions to automatically scale based on the number of requests to the model.
B. Deploy the model on an Amazon Elastic Container Service (Amazon ECS) cluster that uses AWS Fargate. Set a static number of tasks to handle requests during times of peak usage.
C. Deploy the model to an Amazon SageMaker endpoint. Deploy multiple copies of the model to the endpoint. Create an Application Load Balancer to route traffic between the different copies of the model at the endpoint.
D. Deploy the model to an Amazon SageMaker endpoint. Create SageMaker endpoint auto scaling policies that are based on Amazon CloudWatch metrics to adjust the number of instances dynamically.
| Page 4 out of 14 Pages |
| Previous |