- Email support@dumps4free.com

While training a UiPath Communications Mining model, the Search feature was used to pin
a certain label on a few communications. After retraining, the new model version starts to
predict the tagged label but infrequently and with low confidence.
According to best practices, what would be the correct next step to improve the model's
predictions for the label, in the "Explore" phase of training?
A. Use the "Rebalance" training mode to pin the label to more communications.
B. Use the 'Teach" training mode to pin the label to more communications.
C. Use the "Low confidence" training mode to pin the label to more communications.
D. Use the "Search" feature to pin the label to more communications.
Explanation: According to the UiPath documentation, the ‘Teach’ training mode is used to improve the model’s predictions for a specific label by pinning it to more communications that match the label’s criteria. This helps the model learn from more examples and increase its confidence and accuracy. The ‘Teach’ mode also allows you to unpin the label from communications that do not match it, which helps the model avoid false positives. The other training modes are not as effective for this purpose, as they either focus on different aspects of the model performance or do not provide enough feedback to the model.
What is Document Understanding?
A. A solution for combining different approaches to extract information from workflows.
B. A solution that offers the ability to digitize, extract, validate, and train data from documents.
C. A solution for the processing of Excel files for extracting data tables.
D. A solution for combining different approaches to extract entities from Word documents such as contracts and agreements.
Explanation: Document Understanding is a tool that helps you create and manage documents for your automation scenarios in the UiPath ecosystem. It allows you to process and extract data from multiple document types in an open, extensible, and versatile environment. The framework consists of components such as Taxonomy, Digitization, Data Extraction, Data Extraction Validation, Data Extraction Training, and Data Consumption, and enables you to customize and train your own algorithms12.
How many types of synchronization mechanisms exist in the Document Understanding Process to prevent multiple robots to write in a file at the same time?2
A. 2
B. 3
C. 4
D. 5
Explanation: The Document Understanding Process uses two types of synchronization
mechanisms to prevent multiple robots from writing in a file at the same time: file locks and
queues. File locks are used to ensure that only one robot can access a file at a time, while
queues are used to store the information extracted from the documents and to avoid data
loss or duplication. The process uses the following activities to implement these
mechanisms:
File Lock Scope: This activity creates a lock on a file or folder and executes a set
of activities within it. The lock is released when the scope ends or when an
exception occurs. This activity ensures that only one robot can read or write a file
or folder at a time, and prevents other robots from accessing it until the lock is
released.
Add Queue Item: This activity adds an item to a queue in Orchestrator, along with
some relevant information, such as a reference, a priority, or a deadline. The item
can be a JSON object, a string, or any serializable .NET type. This activity ensures
that the information extracted from the documents is stored in a queue and can be
retrieved by another robot or process later.
Get Queue Items: This activity retrieves a collection of items from a queue in
Orchestrator, based on some filters, such as status, reference, or creation time.
The items can be processed by the robot or passed to another activity, such as
Update Queue Item or Delete Queue Item. This activity ensures that the
information stored in the queue can be accessed and manipulated by the robot or
process.
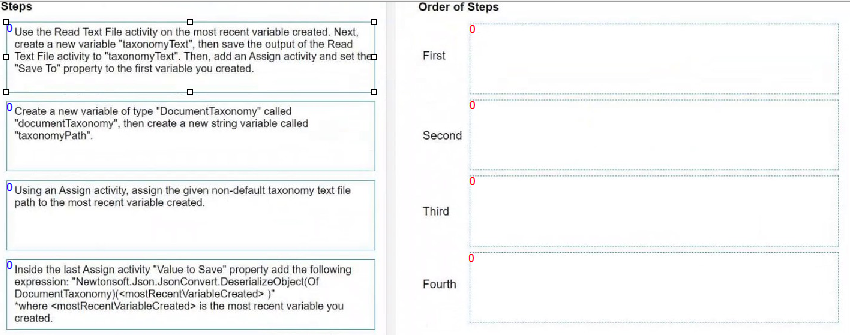
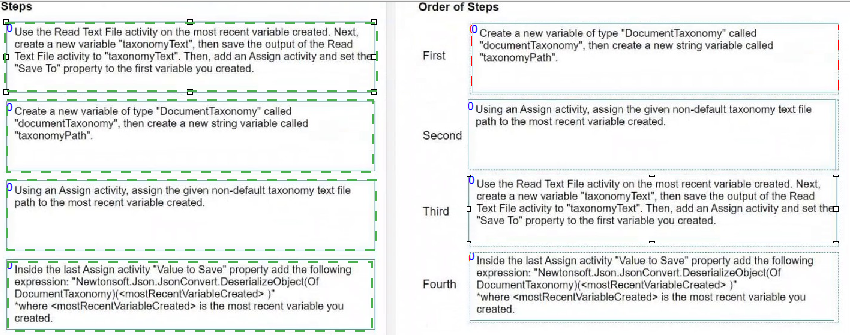
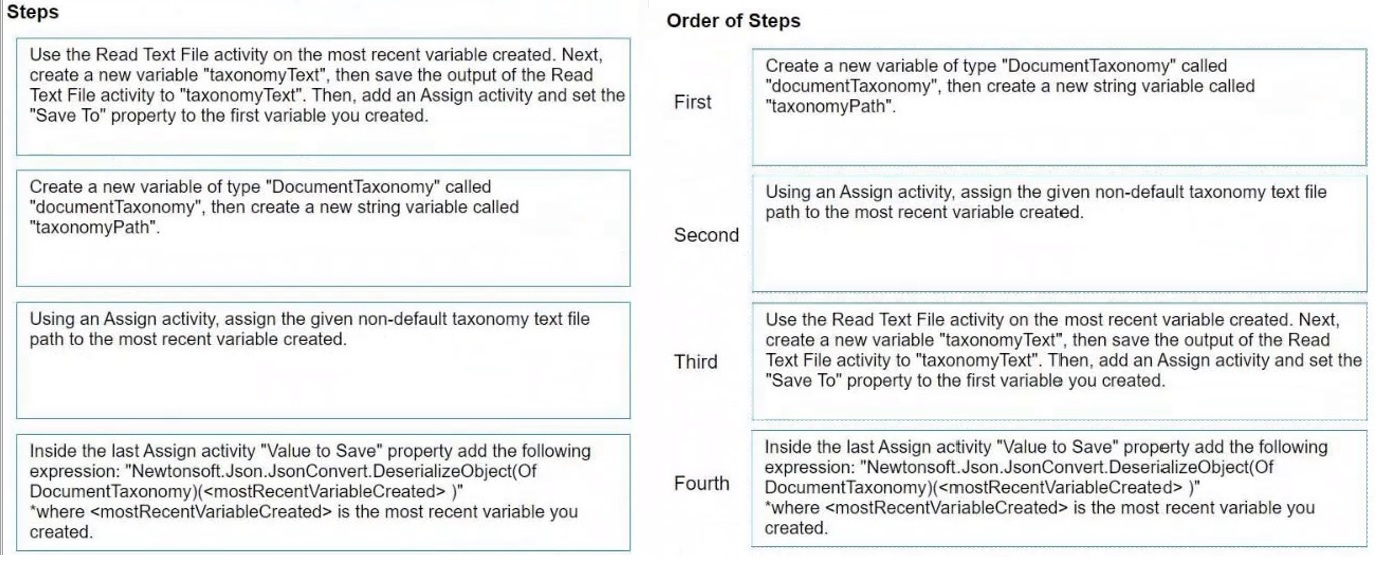
How do you load a taxonomy from a given non-default location text file into a variable?
Instructions: Drag the steps found on the "Left" and drop them on the "Right" in the correct
order.
Explanation:
C:\Users\Waqas Shahid\Desktop\Mudassir\Untitled.jpg
to load a taxonomy from a given non-default location text file into a variable, the order of
steps should be as follows:
Create a new variable of type 'DocumentTaxonomy' called 'documentTaxonomy',
then create a new string variable called 'taxonomyPath'.
Using an Assign activity, assign the given non-default taxonomy text file path to
the most recent variable created.
Use the Read Text File activity on the 'taxonomyPath' variable created. Next,
create a new variable 'taxonomyText', then save the output of the Read Text File
activity to 'taxonomyText'.
Inside the last Assign activity 'Value to Save' property add the following
expression: "Newtonsoft.Json.JsonConvert.DeserializeObject(Of
DocumentTaxonomy)(taxonomyText)" where 'taxonomyText' is the text read from
the file and 'documentTaxonomy' (the most recent variable created) is the variable
you created.
Following these steps in this order will load the taxonomy from a text file into the
'documentTaxonomy' variable in UiPath.
What do entities represent in UiPath Communications Mining?
A. Structured data points.
B. Concepts, themes, and intents.
C. Thread properties.
D. Metadata properties.
Explanation: Entities are additional elements of structured data which can be extracted from within the verbatims. Entities include data such as monetary quantities, dates, currency codes, organisations, people, email addresses, URLs, as well as many other industry specific categories. Entities represent concepts, themes, and intents that are relevant to the business use case and can be used for filtering, searching, and analyzing the verbatims.
| Page 1 out of 16 Pages |