- Email support@dumps4free.com

After uploading a standard file into Marketing Cloud intelligence via total Connect, you noticed that the number of rows uploaded (to the specific data stream) is NOT equal to the number of rows present in the source file. What are two resource that may cause this gap?
A. All mapped Measurements for a given row have values equal to zero
B. Main entity is not mapped
C. The source file does not contain the mediaBuy entity
D. The file does not contain any measurements (dimension only)
Explanation: In Marketing Cloud Intelligence, discrepancies between the number of rows uploaded and the number of rows present in the source file can be caused by several factors. If all mapped measurements for a row are zero, that row may be excluded from the upload, as it does not contribute to the analytics. Additionally, if the main entity, which acts as the primary identifier for records, is not mapped, the system cannot correctly ingest the data as it lacks the necessary reference to organize and store the information.
A client Ingested the following We into Marketing Cloud Intelligence:

The mapping of the above file can be seen below:
Date — Day
Media Buy Key — Media Buy Key
Campaign Name — Campaign Name
Campaign Group -. Campaign Custom Attribute 01
Clicks —> Clicks
Media Cost —> Media Cost
Campaign Planned Clicks —> Delivery Custom Metric 01
The client would like to have a "Campaign Planned Clicks" measurement.
This measurement should return the "Campaign Planned Clicks" value per Campaign, for
example:
For Campaign Name 'Campaign AAA", the "Campaign Planned Clicks" should be 2000, rather than 6000 (the total sum by the number of Media Buy keys).
In order to create this measurement, the client considered multiple approaches. Please review the different approaches and answer the following question:
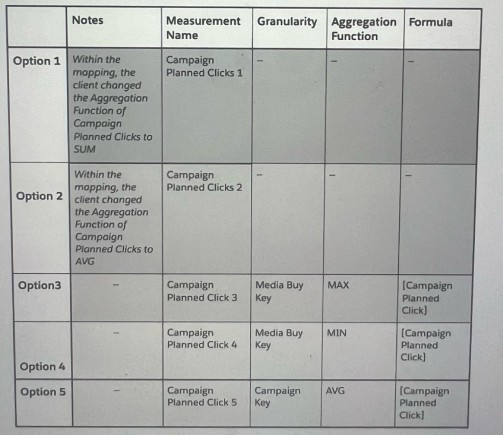
Which two options will yield a false result:
A. Option 2
B. Option 5
C. Option 3
D. Option 4
E. Option 1
Explanation: The goal is to obtain a "Campaign Planned Clicks" value per Campaign, not accumulated by Media Buy keys. Option 1 (SUM aggregation function) would sum all the "Campaign Planned Clicks" across Media Buy keys which would not yield the unique value per Campaign. Similarly, Option 5 (AVG aggregation function at Campaign Key level) would incorrectly average the values. Both options do not provide a way to return a singular "Campaign Planned Clicks" value for each Campaign.
Your client would like to create a new harmonization field - Exam Topic. The below table represents the harmonization logic from each source.
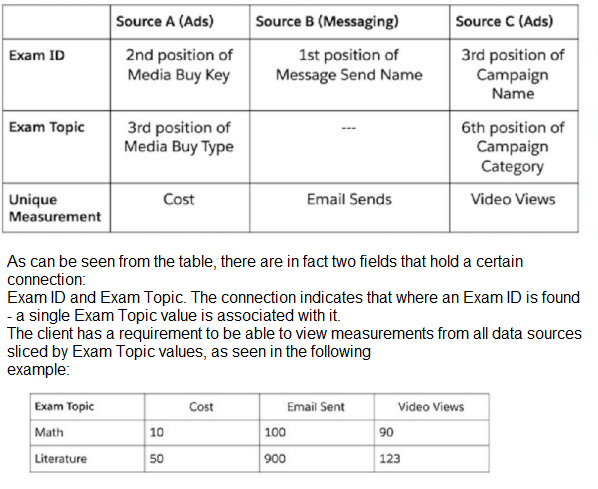
The client suggested to create, without any mapping manipulations, several patterns via the harmonization center that will generate two Harmonized Dimensions:
Exam ID
Exam Topic
Given the above information, which statement is correct regarding the ability to implement this request with the above suggestion?
A. The above Patterns setup will not work for this use case.
B. The solution will work - the client will be able to view Exam Topic with Email Sends.
C. Only if 5 different Patterns are created, from 5 different fields - the solution will work.
D. The Harmonized field for Exam ID is redundant. One Harmonized dimension for Exam Topic is enough for a sustainable and working solution
Explanation: If the harmonization logic consistently associates a single Exam Topic with each Exam ID across all data sources, then creating two harmonized dimensions may be unnecessary. One harmonized dimension for Exam Topic would suffice because it inherently carries the Exam ID's uniqueness within it. The harmonized dimension for Exam Topic would allow the client to slice the data by Exam Topic values, fulfilling the requirement.
A technical architect is provided with the logic and Opportunity file shown below:
The opportunity status logic is as follows:
For the opportunity stages “Interest”, “Confirmed Interest” and “Registered”, the status should be “Open”.
For the opportunity stage “Closed”, the opportunity status should be closed Otherwise, return null for the opportunity status
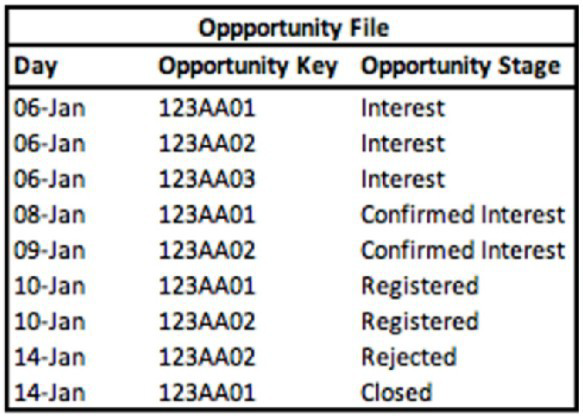
Given the above file and logic and assuming that the file is mapped in a GENERIC data stream type with the following mapping:
“Day” — Standard “Day” field
“Opportunity Key” > Main Generic Entity Key
“Opportunity Stage” — Generic Entity Key 2
“Opportunity Count” — Generic Custom Metric
A pivot table was created to present the count of opportunities in each stage. The pivot table is filtered on January (entire month). What is the number of opportunities in the Interest stage?
A. 1
B. 3
C. 2
D. 0
Explanation: Based on the Opportunity file, the Opportunity Stage of 'Interest' occurs 3 times across unique Opportunity Keys. Since the pivot table is filtered to present the entire month of January and the Opportunity Stage 'Interest' is listed three times with different Opportunity Keys, the count of opportunities in the 'Interest' stage would be 3.
What are two potential reasons for performance issues (when loading a dashboard) when using the CRM data stream type?
A. When a data stream type ''CRM - Leads' is created, another complementary 'CRM - Opportunity' is created automatically.
B. Pacing - daily rows are being created for every lead and opportunity keys
C. No mappable measurements - all measurements are calculated
D. The data is stored at the workspace level.
Explanation: For performance issues when loading a dashboard using CRM data stream
type:
Pacing can create performance issues because daily rows for every lead and opportunity key can result in a very large number of rows, increasing load times. Having only calculated measurements means there are no direct, mappable values to query against, which can increase the computational load and affect performance.
| Page 3 out of 13 Pages |
| Previous |