- Email support@dumps4free.com

Topic 3, Mix Questions
You use Azure Data Lake Storage Gen2.
You need to ensure that workloads can use filter predicates and column projections to filter
data at the time the data is read from disk.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A.
Reregister the Microsoft Data Lake Store resource provider.
B.
Reregister the Azure Storage resource provider.
C.
Create a storage policy that is scoped to a container.
D.
Register the query acceleration feature.
E.
Create a storage policy that is scoped to a container prefix filter.
Reregister the Azure Storage resource provider.
Register the query acceleration feature.
Note: This question is part of a series of questions that present the same scenario.
Each question in the series contains a unique solution that might meet the stated
goals. Some question sets might have more than one correct solution, while others
might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a
result, these questions will not appear in the review screen.
You plan to create an Azure Databricks workspace that has a tiered structure. The
workspace will contain the following three workloads:
A workload for data engineers who will use Python and SQL.
A workload for jobs that will run notebooks that use Python, Scala, and SOL.
A workload that data scientists will use to perform ad hoc analysis in Scala and R.
The enterprise architecture team at your company identifies the following standards for
Databricks environments:
The data engineers must share a cluster.
The job cluster will be managed by using a request process whereby data
scientists and data engineers provide packaged notebooks for deployment to the
cluster.
All the data scientists must be assigned their own cluster that terminates
automatically after 120 minutes of inactivity. Currently, there are three data
scientists.
You need to create the Databricks clusters for the workloads.
Solution: You create a Standard cluster for each data scientist, a High Concurrency cluster
for the data engineers, and a High Concurrency cluster for the jobs.
Does this meet the goal?
A.
Yes
B.
No
Yes
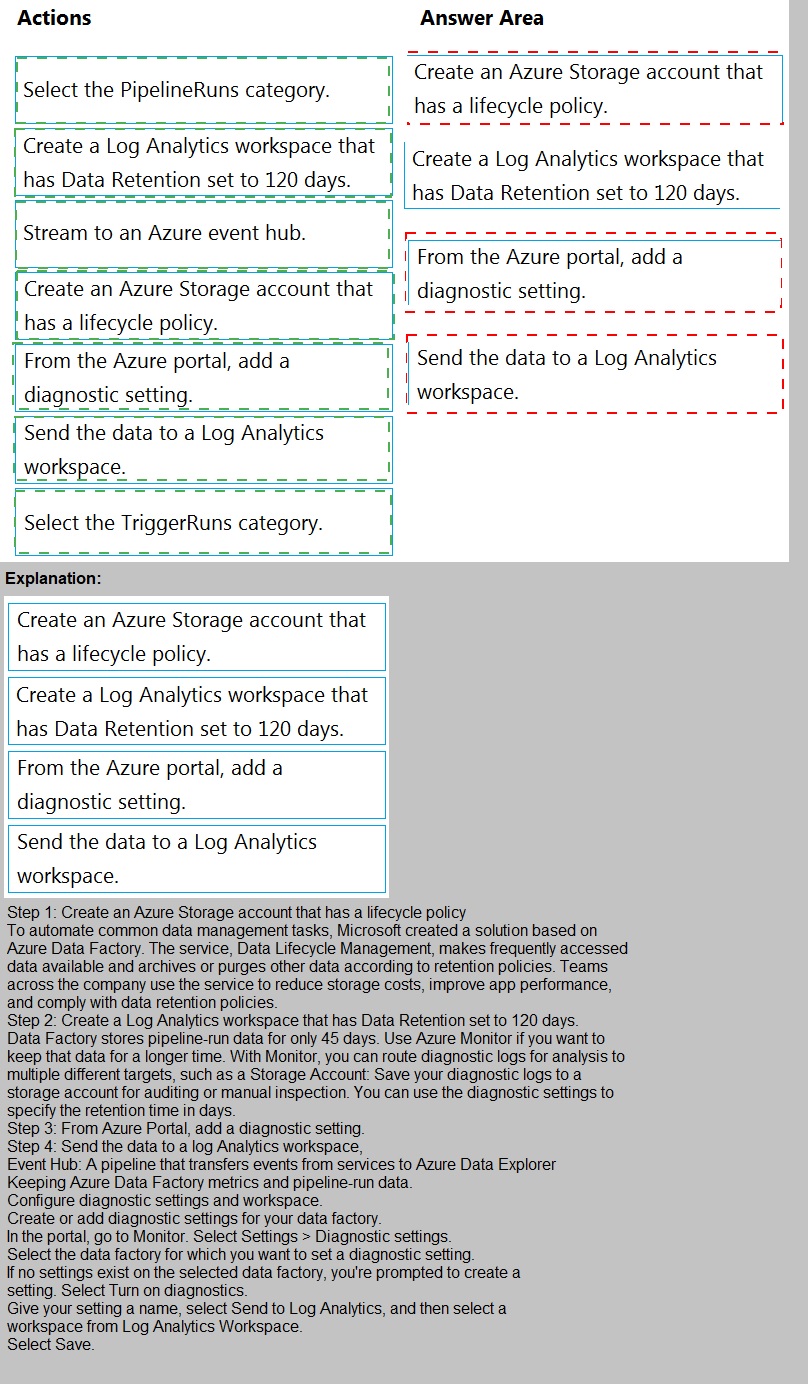
You have an Azure data factory.
You need to ensure that pipeline-run data is retained for 120 days. The solution must
ensure that you can query the data by using the Kusto query language.
Which four actions should you perform in sequence? To answer, move the appropriate
actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of
the correct orders you select.
You have an Azure Data Lake Storage Gen2 container that contains 100 TB of data.
You need to ensure that the data in the container is available for read workloads in a
secondary region if an outage occurs in the primary region. The solution must minimize
costs.
Which type of data redundancy should you use?
A.
zone-redundant storage (ZRS)
B.
read-access geo-redundant storage (RA-GRS)
C.
locally-redundant storage (LRS)
D.
geo-redundant storage (GRS)
locally-redundant storage (LRS)
Note: This question is part of a series of questions that present the same scenario. Each
question in the series contains a unique solution that might meet the stated goals. Some
question sets might have more than one correct solution, while others might not have a
correct solution.
After you answer a question in this scenario, you will NOT be able to return to it. As a
result, these questions will not appear in the review screen.
You have an Azure Storage account that contains 100 GB of files. The files contain text
and numerical values. 75% of the rows contain description data that has an average length
of 1.1 MB.
You plan to copy the data from the storage account to an enterprise data warehouse in
Azure Synapse Analytics.
You need to prepare the files to ensure that the data copies quickly.
Solution: You convert the files to compressed delimited text files.
Does this meet the goal?
A.
Yes
B.
No
Yes
All file formats have different performance characteristics. For the fastest load, use
compressed delimited text files.
Reference:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/guidance-for-loading-data
| Page 9 out of 42 Pages |
| Previous |