- Email support@dumps4free.com

Topic 3, Mix Questions
You are creating an Azure Data Factory data flow that will ingest data from a CSV file, cast
columns to specified types of data, and insert the data into a table in an Azure Synapse
Analytic dedicated SQL pool. The CSV file contains three columns named username,
comment, and date.
The data flow already contains the following:
A source transformation.
A Derived Column transformation to set the appropriate types of data.
A sink transformation to land the data in the pool.
You need to ensure that the data flow meets the following requirements:
All valid rows must be written to the destination table.
Truncation errors in the comment column must be avoided proactively.
Any rows containing comment values that will cause truncation errors upon insert
must be written to a file in blob storage.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A.
To the data flow, add a sink transformation to write the rows to a file in blob storage.
B.
To the data flow, add a Conditional Split transformation to separate the rows that will cause truncation errors.
C.
To the data flow, add a filter transformation to filter out rows that will cause truncation errors.
D.
Add a select transformation to select only the rows that will cause truncation errors.
To the data flow, add a sink transformation to write the rows to a file in blob storage.
To the data flow, add a Conditional Split transformation to separate the rows that will cause truncation errors.
Explanation:
B: Example:
1. This conditional split transformation defines the maximum length of "title" to be five. Any
row that is less than or equal to five will go into the GoodRows stream. Any row that is
larger than five will go into the BadRows stream.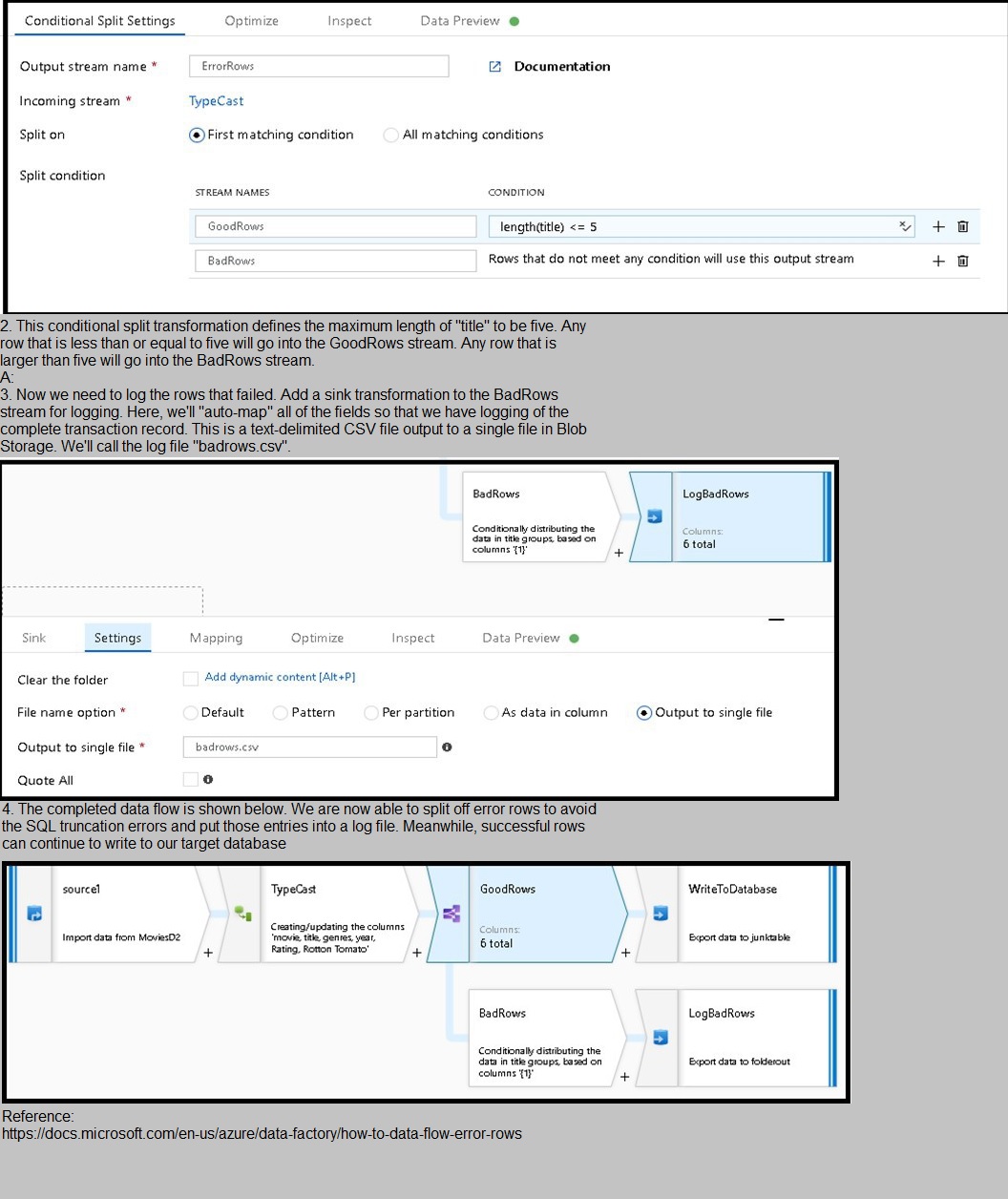
You have a table named SalesFact in an enterprise data warehouse in Azure Synapse
Analytics. SalesFact contains sales data from the past 36 months and has the following
characteristics:
Is partitioned by month
Contains one billion rows
Has clustered columnstore indexes
At the beginning of each month, you need to remove data from SalesFact that is older than
36 months as quickly as possible.
Which three actions should you perform in sequence in a stored procedure? To answer,
move the appropriate actions from the list of actions to the answer area and arrange them
in the correct order.

You have a self-hosted integration runtime in Azure Data Factory.
The current status of the integration runtime has the following configurations:
Status: Running
Type: Self-Hosted
Version: 4.4.7292.1
Running / Registered Node(s): 1/1
High Availability Enabled: False
Linked Count: 0
Queue Length: 0
Average Queue Duration. 0.00s
The integration runtime has the following node details:
Name: X-M
Status: Running
Version: 4.4.7292.1
Available Memory: 7697MB
CPU Utilization: 6%
Network (In/Out): 1.21KBps/0.83KBps
Concurrent Jobs (Running/Limit): 2/14
Role: Dispatcher/Worker
Credential Status: In Sync
Use the drop-down menus to select the answer choice that completes each statement
based on the information presented.
NOTE: Each correct selection is worth one point

You are designing an Azure Synapse Analytics dedicated SQL pool.
You need to ensure that you can audit access to Personally Identifiable information (PII).
What should you include in the solution?
A.
dynamic data masking
B.
row-level security (RLS)
C.
sensitivity classifications
D.
column-level security
column-level security
You are planning a streaming data solution that will use Azure Databricks. The solution will
stream sales transaction data from an online store. The solution has the following
specifications:
* The output data will contain items purchased, quantity, line total sales amount, and line
total tax amount.
* Line total sales amount and line total tax amount will be aggregated in Databricks.
* Sales transactions will never be updated. Instead, new rows will be added to adjust a
sale.
You need to recommend an output mode for the dataset that will be processed by using
Structured Streaming. The solution must minimize duplicate data.
What should you recommend?
A.
Append
B.
Update
C.
Complete
Complete
| Page 4 out of 42 Pages |
| Previous |