- Email support@dumps4free.com

Topic 3, Mix Questions
You have an Azure Synapse Analytics dedicated SQL pool that contains the users shown in the following table.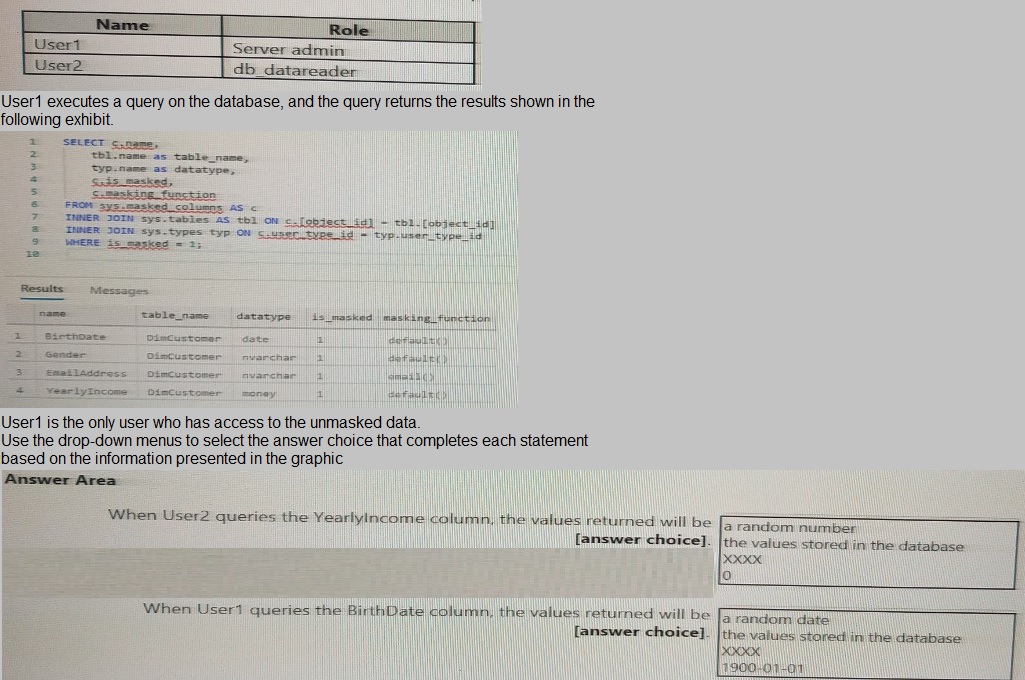
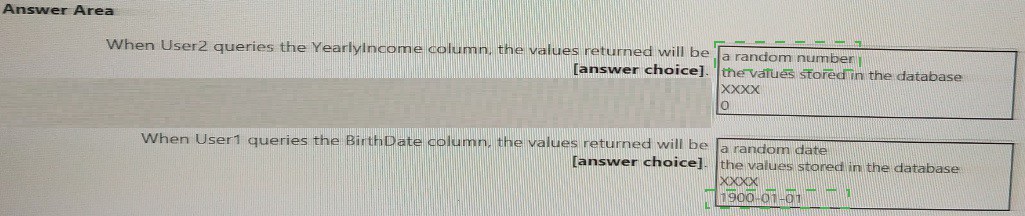
You have an Azure event hub named retailhub that has 16 partitions. Transactions are
posted to retailhub. Each transaction includes the transaction ID, the individual line items,
and the payment details. The transaction ID is used as the partition key.
You are designing an Azure Stream Analytics job to identify potentially fraudulent
transactions at a retail store. The job will use retailhub as the input. The job will output the
transaction ID, the individual line items, the payment details, a fraud score, and a fraud
indicator.
You plan to send the output to an Azure event hub named fraudhub.
You need to ensure that the fraud detection solution is highly scalable and processes
transactions as quickly as possible.
How should you structure the output of the Stream Analytics job? To answer, select the
appropriate options in the answer area.
NOTE: Each correct selection is worth one point
You have a C# application that process data from an Azure IoT hub and performs complex
transformations.
You need to replace the application with a real-time solution. The solution must reuse as
much code as
possible from the existing application
A.
Azure Databricks
B.
Azure Event Grid
C.
Azure Stream Analytics
D.
Azure Data Factory
Azure Stream Analytics
Explanation:
Azure Stream Analytics on IoT Edge empowers developers to deploy near-real-time
analytical intelligence closer to IoT devices so that they can unlock the full value of devicegenerated
data. UDF are available in C# for IoT Edge jobs
Azure Stream Analytics on IoT Edge runs within the Azure IoT Edge framework. Once the
job is created in Stream Analytics, you can deploy and manage it using IoT Hub.
References:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-edge
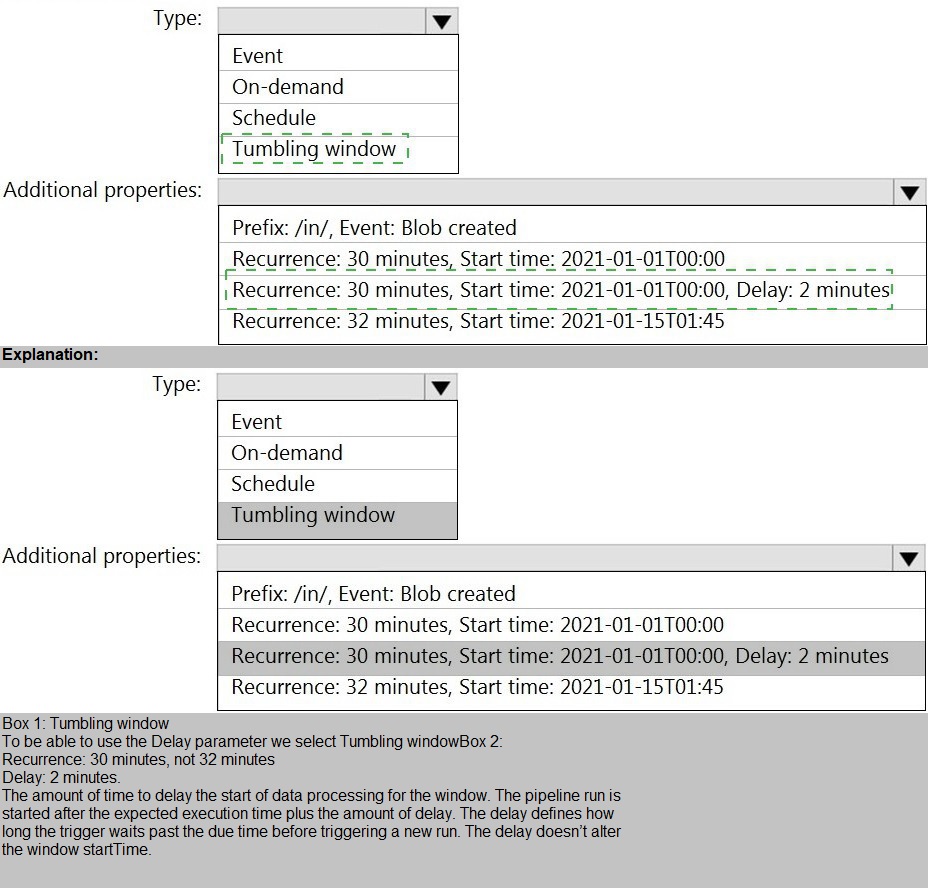
You build an Azure Data Factory pipeline to move data from an Azure Data Lake Storage
Gen2 container to a database in an Azure Synapse Analytics dedicated SQL pool.
Data in the container is stored in the following folder structure.
/in/{YYYY}/{MM}/{DD}/{HH}/{mm}
The earliest folder is /in/2021/01/01/00/00. The latest folder is /in/2021/01/15/01/45.
You need to configure a pipeline trigger to meet the following requirements:
Existing data must be loaded.
Data must be loaded every 30 minutes.
Late-arriving data of up to two minutes must he included in the load for the time at
which the data should have arrived.
How should you configure the pipeline trigger? To answer, select the appropriate options in
the answer area.
NOTE: Each correct selection is worth one point.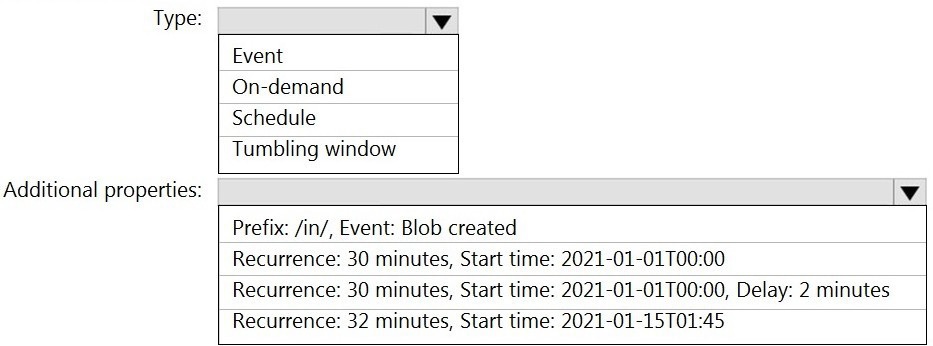
You are designing the folder structure for an Azure Data Lake Storage Gen2 container.
Users will query data by using a variety of services including Azure Databricks and Azure
Synapse Analytics serverless SQL pools. The data will be secured by subject area. Most
queries will include data from the current year or current month.
Which folder structure should you recommend to support fast queries and simplified folder
security?
A.
/{SubjectArea}/{DataSource}/{DD}/{MM}/{YYYY}/{FileData}_{YYYY}_{MM}_{DD}.csv
B.
/{DD}/{MM}/{YYYY}/{SubjectArea}/{DataSource}/{FileData}_{YYYY}_{MM}_{DD}.csv
C.
/{YYYY}/{MM}/{DD}/{SubjectArea}/{DataSource}/{FileData}_{YYYY}_{MM}_{DD}.csv
D.
/{SubjectArea}/{DataSource}/{YYYY}/{MM}/{DD}/{FileData}_{YYYY}_{MM}_{DD}.csv
/{SubjectArea}/{DataSource}/{YYYY}/{MM}/{DD}/{FileData}_{YYYY}_{MM}_{DD}.csv
Explanation:
There's an important reason to put the date at the end of the directory structure. If you want
to lock down certain regions or subject matters to users/groups, then you can easily do so
with the POSIX permissions. Otherwise, if there was a need to restrict a certain security
group to viewing just the UK data or certain planes, with the date structure in front a
separate permission would be required for numerous directories under every hour
directory. Additionally, having the date structure in front would exponentially increase the
number of directories as time went on.
Note: In IoT workloads, there can be a great deal of data being landed in the data store that
spans across numerous products, devices, organizations, and customers. It’s important to
pre-plan the directory layout for organization, security, and efficient processing of the data
| Page 3 out of 42 Pages |
| Previous |